When search results are returned in HydroClient there is the option to view metadata describing the data sets that have been found. This is done by clicking on an individual marker or clicking the Show Search Results button in the search bar. The information presented in the table is important towards interpreting the data sets and finding the data that will serve your purposes best. Here are a few examples of metadata profiles and their respective interpretations.
Example #1: Shale Network

- Publisher: Shale Network
- Service Title: Shale Network
- Keyword: Methane, dissolved
- Site Name: Sugar Run 1.55
- Data Type: Sporadic
- ValueType: Sample
- SampleMedium: Surface water
- QC Level: Unknown
- Method: Collected in 500 mL…
- Collector: Earth and Environmental Systems
From the above metadata, you can discern that this is dissolved methane data collected sporadically as grab samples of surface water. To read the entire method description of how the surface water samples were collected, you can scroll over the description and a pop up will appear. The Quality Control Level is unknown for this data set, but for most other data sets a description is included for the level of quality control that data has been subjected to. It is important to understand the difference between Publisher, Service Title, and Collector:
- Publisher: Person or group publishing the data
- Service Title: Name of Data Service
- Collector: The organization that collects the data
The above information tells you that although the Shale Network group published the data, the Earth and Environmental Systems Institute group originally collected it.
Example #2: U.S Geological Survey NWIS Daily Values Data Service

- Publisher: U.S. Geological Survey
- Service Title: NWIS Daily Values
- Keyword: Discharge, stream
- DataType: Mean
- Value Type: Derived Value
- Sample Medium: Surface Water
- QC Level: Quality controlled data
- Method: Unknown
- Collector: USGS
- TimeUnit: Day
- TimeSupport: 1
- IsRegular: True
From this information, you can see that this is a daily average of discharge of surface water. It is derived from stage observations and, according to this metadata, is measured at a regular frequency and is quality controlled data. This example is different from the Shale Network example in that the U.S. Geological Survey collected and published the data.
Example #3: Understanding the Quality Controlled Data From the U.S Geological Survey NWIS Data Service
When viewing USGS NWIS data series in the search results table, you will notice the QC level is either “Quality controlled data” or “Unknown”. However, after you download the data or plot it with the Data Series Viewer, a more descriptive quality control level is provided. In the Example below, the data series discovered appears to be one single series, yet in the Data Series Viewer you’ll notice there are actually two different data series with two quality controls. The first data series (plotted in red below) has a quality control level of “(A)Approved for publication – Processing and review completed.” The second data series (plotted in green below) has a quality control level of “(P)Provisional data subject to revision.” In this case the older data has been approved for publication, while the newer data is provisional and still under review.
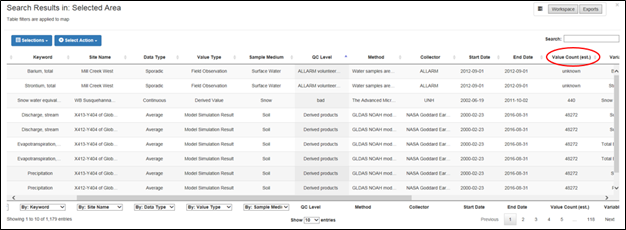
Example #4: Understanding the Estimation for Value Counts
For data series that are regularly sampled, we provide an estimated value count in the table of search results, as shown below. To calculate the estimation, we make the assumption that all data values are equally distributed over the entire time period, from start to end date. From there, we use the ratio between the time range of your search query and the overall time range of the data series to calculate the estimated value count for that particular subset of time. For those data series that are irregularly spaced over time, we cannot provide an estimation.
0 Comments